最佳实践
场景一 · Oncall 答疑
值班群 / 跨团队咨询 / 对外答疑——群里任何人都能 @ 机器人提问。
- 用一台干净的专用 Devbox:给 oncall 单独起一台干净的 Devbox 部署,这样不怕值班/外部人员把你个人的开发环境搞乱。
- 配 oncall 机器人的角色:用
/role set(本群)或/role team set(跨群默认)写好人设与边界。可以搞多个机器人对应不同的开发目录,各管一摊。 - 把权限/边界写进默认角色:典型的 oncall 角色 prompt(在群里发
/role set后贴):
- 排查用 worktree、收尾要清理:在独立 git worktree 里排查,排查完记得删掉,别污染主仓库。
- 提 MR 的身份也可以在默认角色里写死,避免提错人。
- 配
/oncall bind <项目目录>,群内即问即答、跳过选仓库。权限分层兜底:群里所有人可问(canTalk),/cd/restart/close等操作仍只有 owner(allowedUsers)能动。
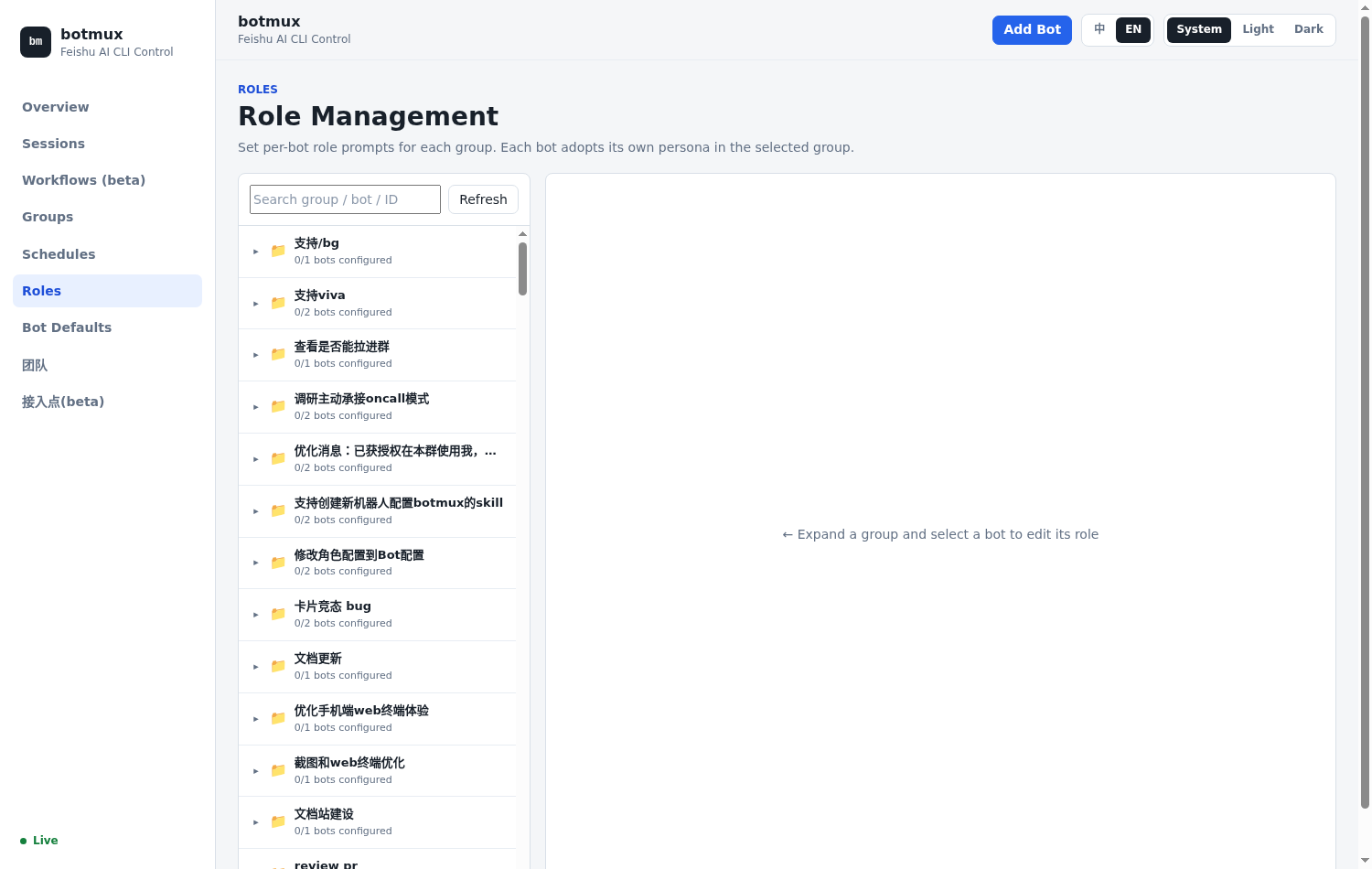
在 Dashboard 的 Roles 面板可以可视化给每个群里的每个 bot 配角色:
场景二 · 报警运维
监控告警 / CI / 工单触发——让外部系统主动把事推给机器人处理。
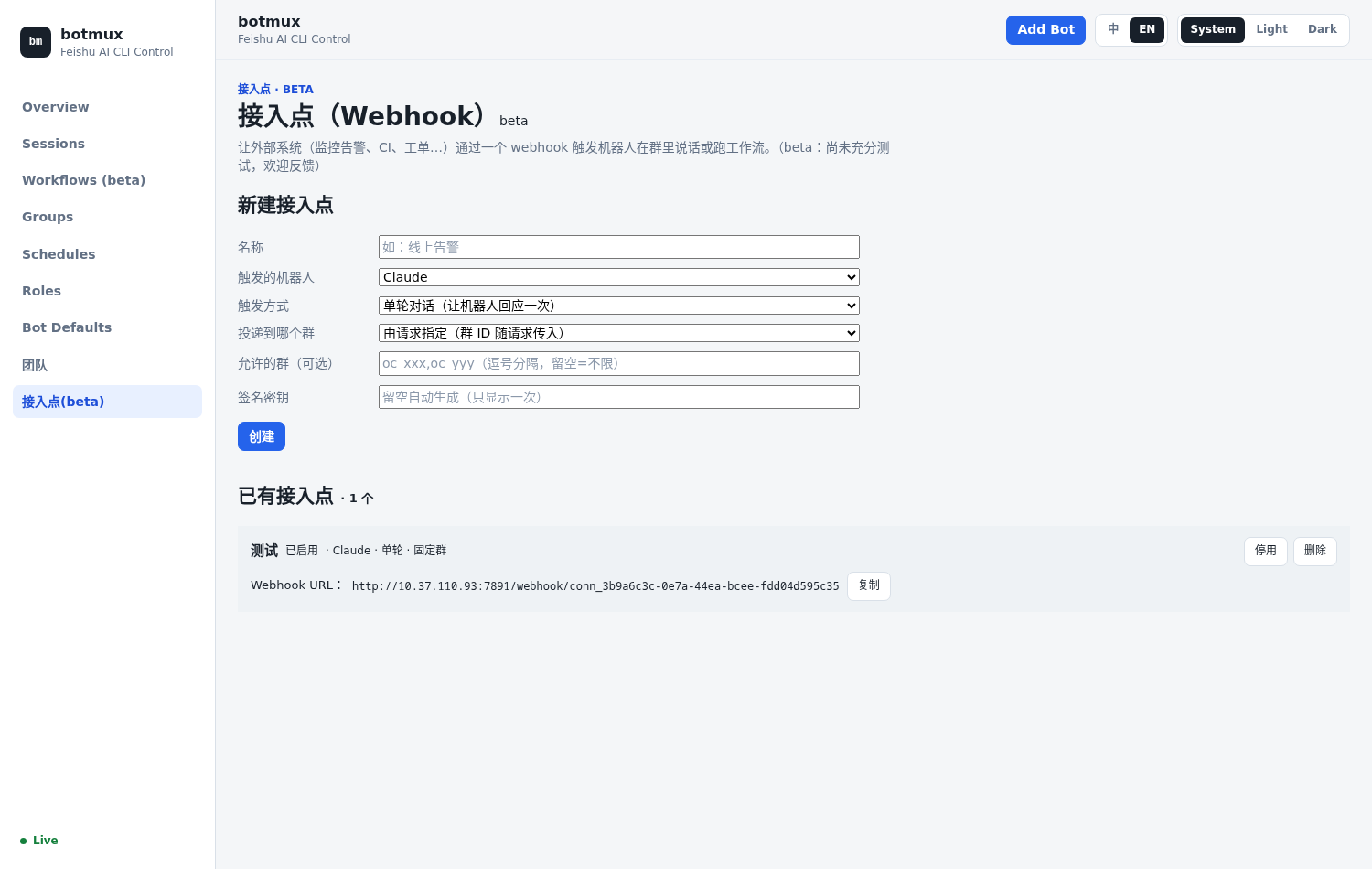
- 试用 Webhook 接入点(Dashboard「接入点(beta)」):让外部系统(监控告警、CI、工单…)通过一个 webhook 触发机器人在群里说话或跑工作流。可配:触发的机器人、触发方式(单轮对话 / 工作流)、投递到哪个群、签名密钥。
- 每个报警自动拉群:可以配成「每来一个报警先自动建一个报警群、把机器人自动拉进去」(按去重键合并同类报警,报警恢复自动关群),值班同学直接在群里跟进。
- 不同项目对应不同的报警机器人:给每个项目一个报警机器人,各自配好带项目背景的默认角色 prompt。
- 不同报警机器人配不同的 oncall 目录:每个报警机器人
/oncall bind到对应项目目录,报警进来直接在那个仓库里排查。 - 也可叠加定时任务做主动巡检播报:
/schedule 每天9:00 检查昨天的报警趋势并总结,异常才 @ 人。
场景三 · 个人研发
一个人,多机器人协作开发。
- 多机器人对应不同 CLI:建多个 bot 分别绑不同 CLI(Claude Code / Codex / …),按任务挑顺手的。
- 同一个 CLI 也能多机器人互审:既可以是不同模型互相 review,也可以是同一模型多个机器人以 sub-agent 的方式互审——多一双眼睛更稳。
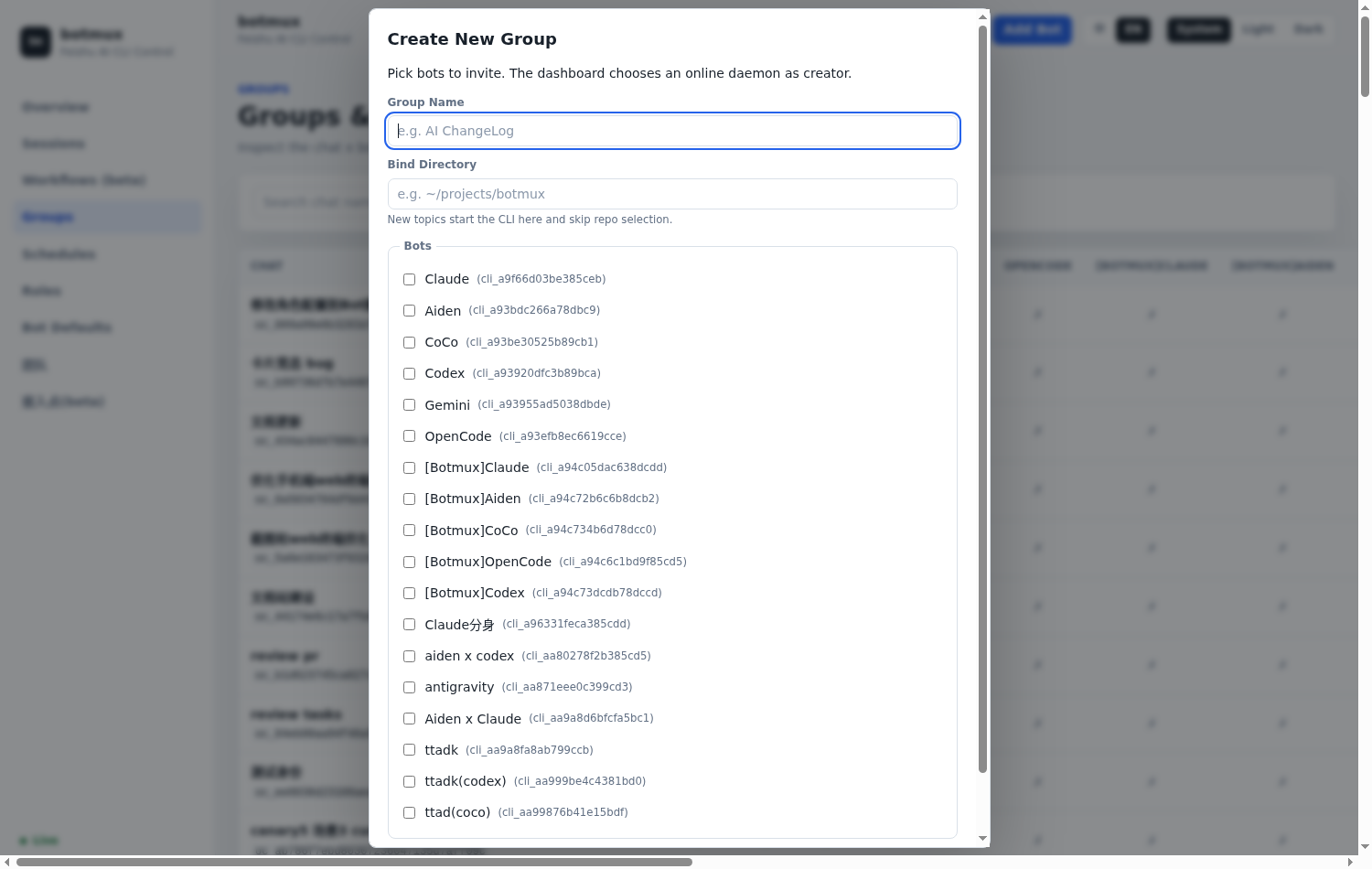
- 多用
/g(=/group) 拉群协作:一个群拉多个机器人一起开发同一个需求;或者用话题群「一个话题一个需求」,上下文天然隔离。 - 给每个机器人设角色分工:有的负责开发、有的负责 review,配合
/role+/role cap能力标签,协作不打架。
场景四 · 多人协作
团队里多个人、各自的机器人一起干活。
- 飞书的限制:不同人名下的机器人默认互相感知不到(收不到对方在群里的消息)。
- 方式一 · introduce:先
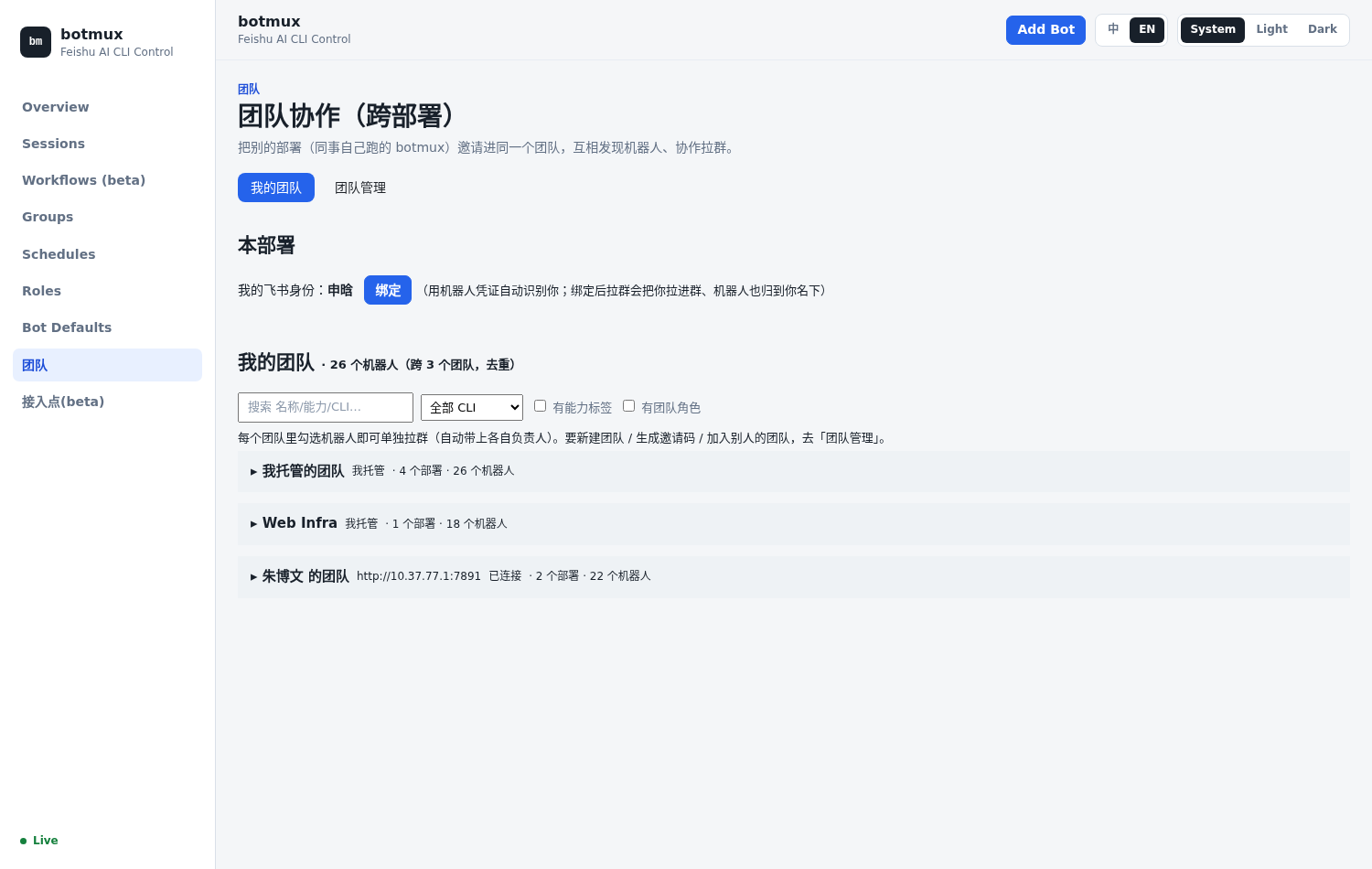
@大家的 bot /introduce让它们彼此建立感知(登记 open_id),然后由一个主机器人给其他机器人分工协作。 - 方式二 · 团队功能(推荐,免 introduce):在 Dashboard「团队」里把多个人名下的 Bot 打上标签、拉到一个团队,跨部署互相发现,直接勾选拉群开协作——不用每次都 introduce。
通用建议(各场景适用)
- 三端无缝协同:装 tmux → 会话常驻、daemon 重启不丢上下文;电脑上的 CLI 用
/adopt接进飞书,手机继续;要动手点「🔑 获取操作链接」拿可写 Web 终端。 - 常开 + 自启:部署在常开的开发机 / 服务器,配
botmux autostart enable重启自恢复。 - 及时清理:会话用完顺手
/close;积压了用 Dashboard 批量关或botmux delete stopped清僵尸。
本页大纲